【Cloud Native】06 K8S 工作负载
【Cloud Native】06 K8S 工作负载
什么是工作负载(Workloads)?
- 工作负载是运行在 Kubernetes 上的一个应用程序。
- 一个应用很复杂,可能由单个组件或者多个组件共同完成
无论怎样,我们可以用一组Pod来表示一个 工作负载(应用程序)
- 所以,在Kubernetes中,Pod是最小的管理单元,包含一个或者一组紧密关联的容器但是,
- 单独的Pod并不能保障总是可用,比如我们创建一个nginx的Pod,因为某些原因,该Pod被意外删除,我们希望其能够自动新建一个同属性的Pod。
- 为此,Kubernetes实现了一系列控制器来管理Pod,使Pod的期望状态和实际状态保持一致.目前常用的控制器有:
- Deployment
- ReplicaSet
- ReplicationController
- StatefulSet
- DaemonSet
- Job/Cronjob
- Deployment
深入理解Pod
pod基础
- deployment创建pod:
- 在部署第一个应用程序中创建Deployment后,k8s创建了一个pod(容器组)来放置应用程序实例(container容器)
- 每个pod都与运行它的worker节点(node)绑定,并保持在那里直到终止或被删除。
- 如果节点 (node)发生故障,则会:
- 在集群中的其他可用节点 (node) 上运行相同的pod
- 从同样的镜像创建container,使用相同的配置,ip地址不同,pod名字不同。
- pod容器组是一个k8s中一个抽象的概念,用于存放:
- 一组 container (可包含一个或多个 container容器),
- 以及这些container(容器)的一些共享资源。
- 这些资源包括:
- 共享存储,称为卷 (Volumes)
- 网络,每个pod (容器组) 在集群中有个唯一的ip,pod(容器组)中的container(容器)共享该ip地址
- container(容器)的基本信息,例如容器的镜像版本,对外暴露的端口等
- 例如:
- pod可能即包含带有 java 应用程序的 container 容器,也可以包含另一个非 Java 的 container 容器。
- pod中的容器共享ip地址和端口空间 (同一pod中的不同container端口不能相互冲突),始终同node位置并共同调度,并在同一node节点上的共享上下文中运行。
- 同一个pod内的容器可以使用localhost+端口互相访问。
- 所以:
- 如果多个容器紧密耦合并且需要共享磁盘等资源,则他们应该被部署在同一个pod (容器组)中。
pod恢复能力
- Pod对容器有自恢复能力 (Pod自动重启失败的容器)
- Pod自己不能恢复自己,Pod被删除就真的没了
- k8s集群能自己在其他地方再启动这个Pod
- Pod 天生地为其成员容器提供了两种共享资源: 网络和存储。
pause容器
- kubelet启动一个Pod,准备两个容器
- 一个是Pod声明的应用容器 (nginx)
- 另外一个是Pause。Pause给当前应用容器设置好网络空间各种的。
一个Pod由一个Pause容器设置好整个Pod里面所有容器的网络、名称空间等信息
- 每个pod中都存在一个pause容器。在 Pod 启动时,pause容器总是创建的第一个容器.
这个是k8s自动创建的,是pod 的根容器。
- 作用:
- 打破容器间隔离,共享某些信息:
- 在Docker容器世界里边,容器之间原本是被 Linux Namespace 和 cgroups 隔开的。但是,同一个的Pod内部的多个容器,需要打破这种隔离。
- 那么,Pod是怎么去打破这个隔离,然后共享某些事情和某些信息。这就是 Pod 的设计要解决的核心问题所在。
- 管理一组容器
- 在一组容器作为一个单元的情况下,难以对整体的容器简单地进行判断及有效地进行行动。
- 比如,一个容器死亡了,此时是算整体挂了么?
- 那么引入与业务无关的Pause容器作为Pod的根容器以它的状态代表着整个容器组的状态,这样就可以解决该问题。
- 打破容器间隔离,共享某些信息:
- 如何实现:
- 回到Docker,打破容器隔离,可以通过创建一个父容器实现
- 例如:
- (1) 创建容器A,作为父容器,容器ID假设为AID
- (2) 创建容器B,作为子容器,容器ID假设为BID,启动时指定PID命名空间标识为 – pid=container:AID
- (3) 创建容器C,作为子容器,容器ID假设为CID,启动时指定PID命名空间标识为 – pid=container:AID
- 此时,容器B与容器C共享相同的PID命名空间(即容器A的PID命名空间),这样,就实现了 PID 命名空间的共享。
总之,在Kubernetes中,pause容器作为您pod中所有容器的父容器,根容器,也叫Infra container
- pause容器 (Infra container) 有多个核心职责
- (1),它作为在pod中共享Linux名称空间的基础容器
- (2),启用PID(进程ID)名称空间共享后,它将作为每个pod的PID 1进程(根进程),并回收僵尸进程。
- (3),共享Pause容器挂载的Volume,这样简化了业务容器之间的通信问题,也解决了容器之间的文件共享问题
(4),共享Pause容器所分配的网络资源或者 Network Namespace,共享给整个 Pod 的其他容器其他所有容器都会通过Join Namespace 的方式加入到Infra container 的 Network Namespace 中。
- pause容器 (lnfra container) 是一个非常小的镜像,大概 700KB 左右,是一个 C语言写的、永远处于“暂停”状态的容器。
- 由于有了这样一个Infra container 之后,其他所有容器可以共享存储和网络,其他容器都会通过JoinNamespace 的方式加入到 Infra container 的核心的Namespace 中。
pod 的不同容器
- 标准容器 (应用容器) Application Container。
- 初始化容器 Init Container。
- Pod的Init 初始化容器,就是init容器成功启动,应用Pod才能开始启动。
- 比如:
- 数据库启动完成后,才能开始启动应用
- 在init容器中,根据需要生成配置文件,然后在主应用pod中启动应用
- 边车容器 Sidecar Container。
- 临时容器 Ephemeral Container.
- debug 容器也叫做 临时容器。
- 临时容器共享了Pod的所有的命名空间
- 临时容器有Debug的一些命令,排错完成以后,只要exit退出容器,临时容器自动删除
一般来说,我们部署的大多是标准容器 (Application Container)
pod, node关系
- pod(容器组)总是在node (节点) 上运行。
- node(节点)是kubernetes集群中的计算机节点。可以是物理机或虚拟机。每个node (节点)都由master管理。
- 一个node (节点) 上可以部署多个pod (容器组),kubernetes master会根据每一个node (节点)上的可用资源情况,自动调度pod (容器组) 到最佳的node (节点)上。
pod使用
- 我们一般不直接创建Pod,而是创建一些工作负载由他们来创建Pod
pod生命周期
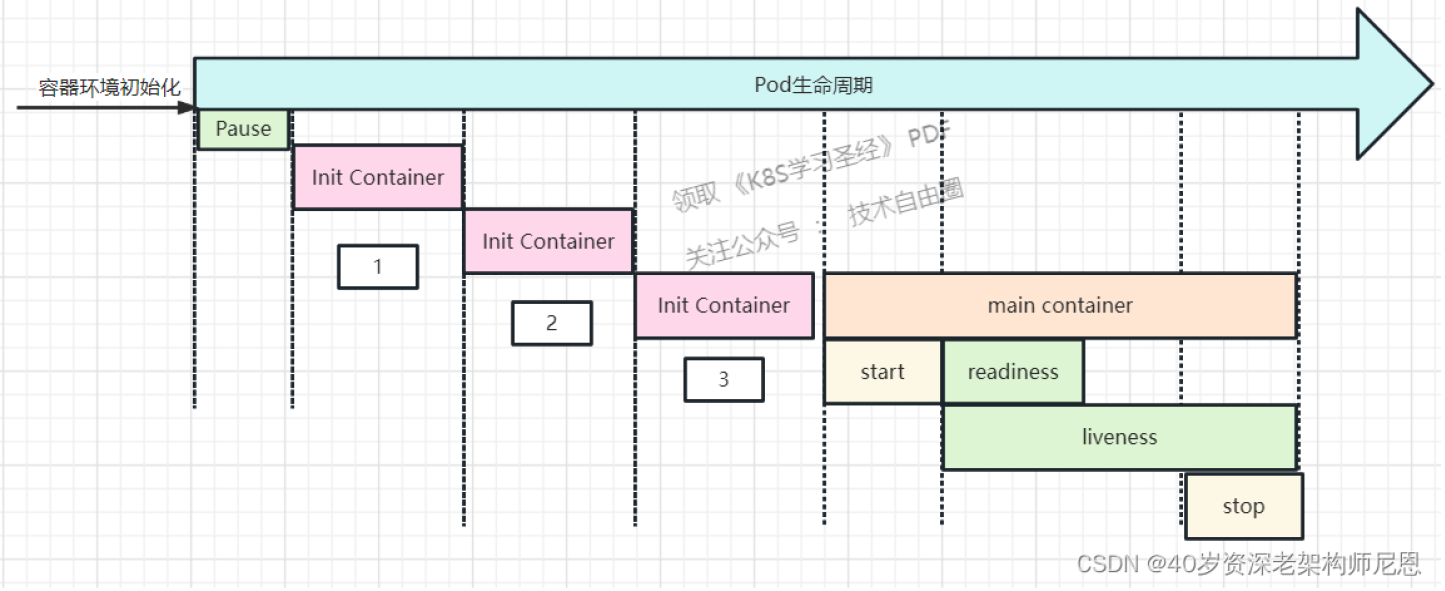
pod创建过程
- 运行初始化容器 (init container) 过程
- 比如有3个初始化容器1、2、3,那么会按顺序把1、2、3的InitC都串行执行初始化。
- 只有当所有的初始化容器执行完后,对应的主容器才会启动;
- 如上图所示,会按顺序把1、2、3的InitC都执行完成之后,才进入Main Container阶段
- 运行主容器 (main container)
- 容器启动后钩子(post start)
- 这个阶段是主容器运行之后立即需要做的事;
- 注意由于是异步执行,它无法保证一定在 ENTRYPOINT 之前运行.
- 如果失败,容器会被杀死,并根据 RestartPolicy 决定是否重启
- 就绪性探测 (readiness probe)
- 就绪检测,检测成功后,Pod状态改为Ready
- 容器的存活性探测 (liveness probe)
- 健康/生存检测
- 容器启动后钩子(post start)
pod终止过程
- 容器终止前钩子(pre stop)
- 这个阶段主要做容器即将退出前需要做的事。
- 在容器终止之前调用,是同步阻塞的,需要执行完该步骤后,才能真正执行终止容器的步骤。
- 常用于资源清理
- 执行完成之后容器将成功终止,如果失败,容器同样也会被杀死
- 在其完成之前 会阻塞删除容器的操作
pod的回调
- 支持定义回调动作的方式:
- exec: 在容器内执行命令,如果命令的退出状态码是0 表示执行成功,否则表示失败
- httpGet: 向指定 URL发起 GET 请求,如果返回的 HTTP 状态码在[200,400)之间表示请求成功,否则表示失败
- tcpSocket: 检查容器TCP状态,如果能连接则正常 (eg: 连接数据库3389)
- sleep: 延迟指定时间
- 文档:
- https://zhuanlan.zhihu.com/p/643974167
- https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/attach-handler-lifecycle-event/
- https://kubernetes.io/zh-cn/docs/concepts/containers/container-lifecycle-hooks/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
lifecycle:
postStart:
exec:
command: ["/bin/bash","-c", "echo 'test' >/usr/share/nginx/html/index.html"]
preStop:
exec:
command: ["/bin/bash","-c","nginx -s stop"]
ports:
- containerPort: 80
name: http
pod的探针
- 探针类型:
- 启动探针(StartupProbe)
- kubelet 使用启动探针,来检测应用是否已经启动。如果启动就可以进行后续的探测检查
- 慢容器一定要指定启动探针。否则就一直在等待启动
- 启动探针是一次性的,探测成功以后就不用了,剩下存活探针和就绪探针持续运行
- 如果配置了这类探针,它会禁用存活检测和就绪检测,直到启动探针成功为止。
- 不满足:
- startupProbe 对 Pod 的处置跟livenessProbe 方式相同,失败重启
- 存活探针(LivenessProbe)
- kubelet 使用存活探针来检测容器是否正常存活
- 有些容器可能产生死锁[应用程序在运行,但是无法继续执行后面的步骤],如果检测失败就会重新启动这个容器
- 如果一个容器的存活探针失败多次,kubelet 将重启该容器。
- 不满足:
- 如果不满足健康条件,那么 Kubelet 将根据Pod 中设置的 restartPolicy (重启策略) 来判断,Pod 是否要进行重启操作。
- 当检测失败后,将 Pod的IP:Port 从所在的svc的 EndPoint列表中删除
- 就绪探针(ReadinessProbe)
- kubelet 使用就绪探针,来检测容器是否准备好了可以接收流量。
- 当一个 Pod 内的所有容器都准备好了,才能把这个 Pod 看作就绪了。
- 就绪探针用途就是:
- Service后端负载均衡多个Pod,如果某个Pod还没就绪,就会从service负载均衡里面剔除,不会放流量进来
- 这种探针在等待应用执行耗时的初始任务时非常有用,例如建立网络连接、加载文件和预热缓存。
- 不满足:
- 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施.
- 启动探针(StartupProbe)
- 探针探测方法:
- exec
- httpGet
- tcpSocket
- grpc
启动探针:
- 为什么要启动探针:
- 本质上讲,是将启动探测从 存活探测 的过程中剥离,或者解耦。
- 之前,livenessProbe 身兼多职,既要负责 存活探测,又要负责 启动探测。会导致应用对于慢启动应用而言,存活探测需要比较长时间,
- 如果把那么长的时间,用于存活探测,死亡很长时间之后,才能被发现。
- 所以,对于慢启动应用,可专门设置一个存活探针,各司其职。
- 启动探针和存活探针区别:
- startupProbe 和livenessProbe 最大的区别就是startupProbe在探测成功之后就不会继续探测了,而livenessProbe在pod的生命周期中一直在探测。
- 文档
- https://kubernetes.io/zh-cn/docs/concepts/configuration/liveness-readiness-startup-probes/
- https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
其他:
- 在对于对容器的健康状态检查和就绪状态检查的时候,我们也可以定义开始检查的延迟时长;
- 为啥要开始检查的延迟时长呢?因为有些容器存在容器显示running状态?
- 比如java 服务,有的时候启动要30s以上,内部程序还没有初始化
- 如果立即做健康状态检查,可能存在健康状态为不健康,从而导致容器重启的状况:
- 为啥要开始检查的延迟时长呢?因为有些容器存在容器显示running状态?
- Pod只要是NotReady,Pod就不对外提供服务了
pod状态
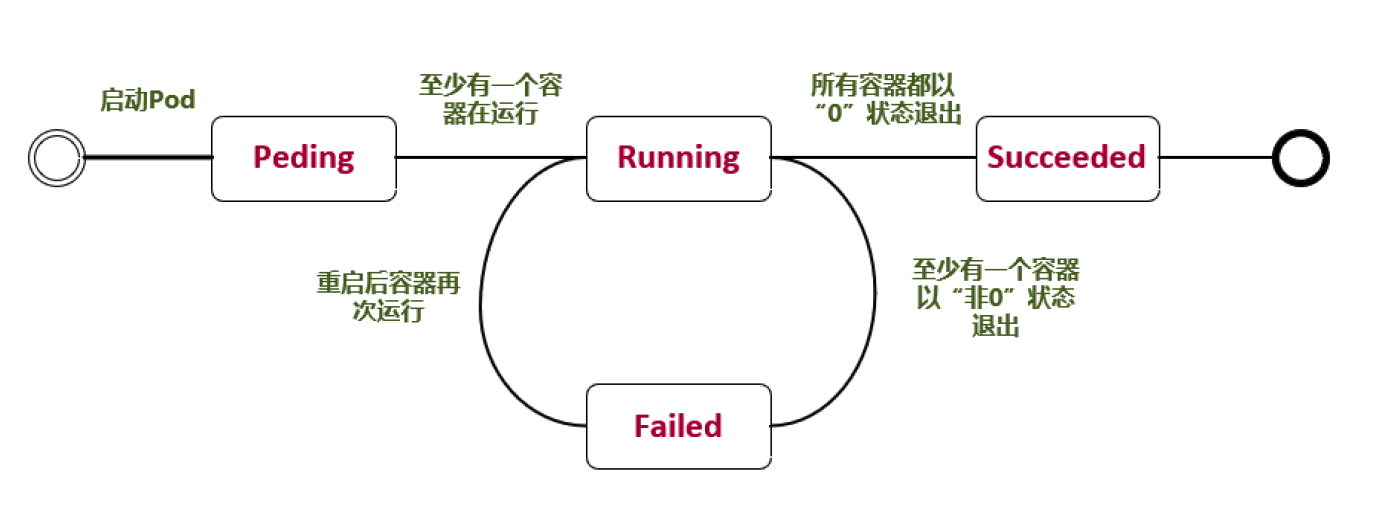
Pod 常见的状态
Pending: 挂起,
- 我们在请求创建pod时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件。
- 已经创建了但是没有适合它运行的节点叫做挂起,
- 这其中也包含集群为容器创建网络,或者下载镜像的过程。
Running:
- Pod内所有的容器都已经被创建,且至少一个容器正在处于运行状态、正在启动状态或者重启状态。
Succeeded:
- Pod中所有容器都执行成功后退出,并且没有处于重启的容器
Failed :
- Pod中所以容器都已退出,但是至少还有一个容器退出时为失败状态
Unknown:未知状态
- pod是什么状态是apiserver和运行在pod节点的kubelet进行通信获取的
- 如果节点之上的kubelet本身出故障,那么apiserver就连不上kubelet,得不到信息了,就会看Unknown
pod资源限制
Pod资源限制:
- 分为 requests 和 1imits,是 Pod 内所有容器所消耗资源的总和。
- requests:
- 定义容器运行时至少需要资源,定义了容器使用资源的最低保障.
- requests会影响到节点的调度,节点内所有pod 的requests加起来,不能超过节点资源。
- limits:
- limits属性定义容器运行时最多能分配的资源,定义了容器可以使用资源的上限。
- limits 不会影响节点的调度,所有pod加起来可以超过节点资源.
计算方式:
- CPU计算方式为:1核 等于 1000m
- 内存计算方式为:按照通常的计算方式计算
注意:
- CPU为可压缩资源,当节点内部资源紧张的时候,会压缩每个pod的CPU资源
- 而内存为不可压缩资源,当节点内部资源开始紧张后,会直接被OOM进程杀死.
- 关于OOM:
- oom-kill就是out-of-memory,
- 在linux内核中有一层保护机制,用于避免linux在内存不足的时候不至于严重的问题,把无关紧要的进程杀掉
- 关于OOM:
- 虽然容器受到 requests 和 limits的使用限制,但是,在容器里边使用 top 命令在容器内看到的资源总数,会是节点级别的可用总量。
Pod重启策略
根据 restartpo1icy来定义重启策略
- A1ways : 但凡 Pod 对象终止就将其重启,此为默认设定
- onFaiTure: 仅在 Pod 对象出现错误时方才将其重启。
- Never : 从不重启。
Pod 的重启,只会在当前同一node 节点上尝试重启 Pod。
重启时间不同:
- 只有第一次重启是立刻执行,
- 后面需要重启时,kubelet 会延迟时间进行,且反复的重启操作的延迟时长依次为 10秒、20秒、40秒、80秒、160秒和300秒,300秒是最大延迟时长。
静态pod
说明
- 静态pod直接由某个节点上的kubelet程序进行管理
- 静态pod不需要 apiserver 介入,静态pod也不需要关联任何 RC,完全是由kubelet程序来监控,不受Deployment和DaemonSet控制。
- 当kubelet发现静态pod停止掉的时候,重新启动静态pod。
- 并且始终在某一个节点上运行
- kubelet会自动为每一个静态Pod在 apiserver 上创建一个Pod,因此可以在 apiserver 中查询到该 pod,但不能通过 apiserver 进行控制 (例如不能删除)
创建:
- 首先
systemctl status kubelet找到kubelet配置文件 - 配置文件增加配置项
- 重启kubelet
- 将 静态pod yaml 放到目录下
- kubelet 会自动创建pod
删除:
- 删除静态pod,直接删除静态pod的yaml文件即可
- 也可以挪出到其他目录,kubelet会自动删除
作用:
- 因为使用静态Pod可以有效预防通过kubectl、或管理工具操作的误删除,可以利用它来部署一些核心组件应用,保障应用服务总是运行稳定数量和提供稳定服务。
文档:
- https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/static-pod/
- https://blog.csdn.net/weixin_51617086/article/details/127533265
This post is licensed under CC BY 4.0 by the author.