【Cloud Native】02 K8S 8大宏观架构
0 文档
reference:
1 K8S的核心价值:带领大家从 容器管理的石器时代,进入工业时代
首先,回顾一下, 在石器时代,我们是怎么管理容器的:
- docker 命令 (石器时代早期)
- docker 编排 (石器时代晚期期)

1.1 K8S 宏观架构
K8S,是一个围绕容器打造的分布式系统,和其他的分布式系统比如rocketmq、kafka、elasticsearch,其实宏观上非常类似.
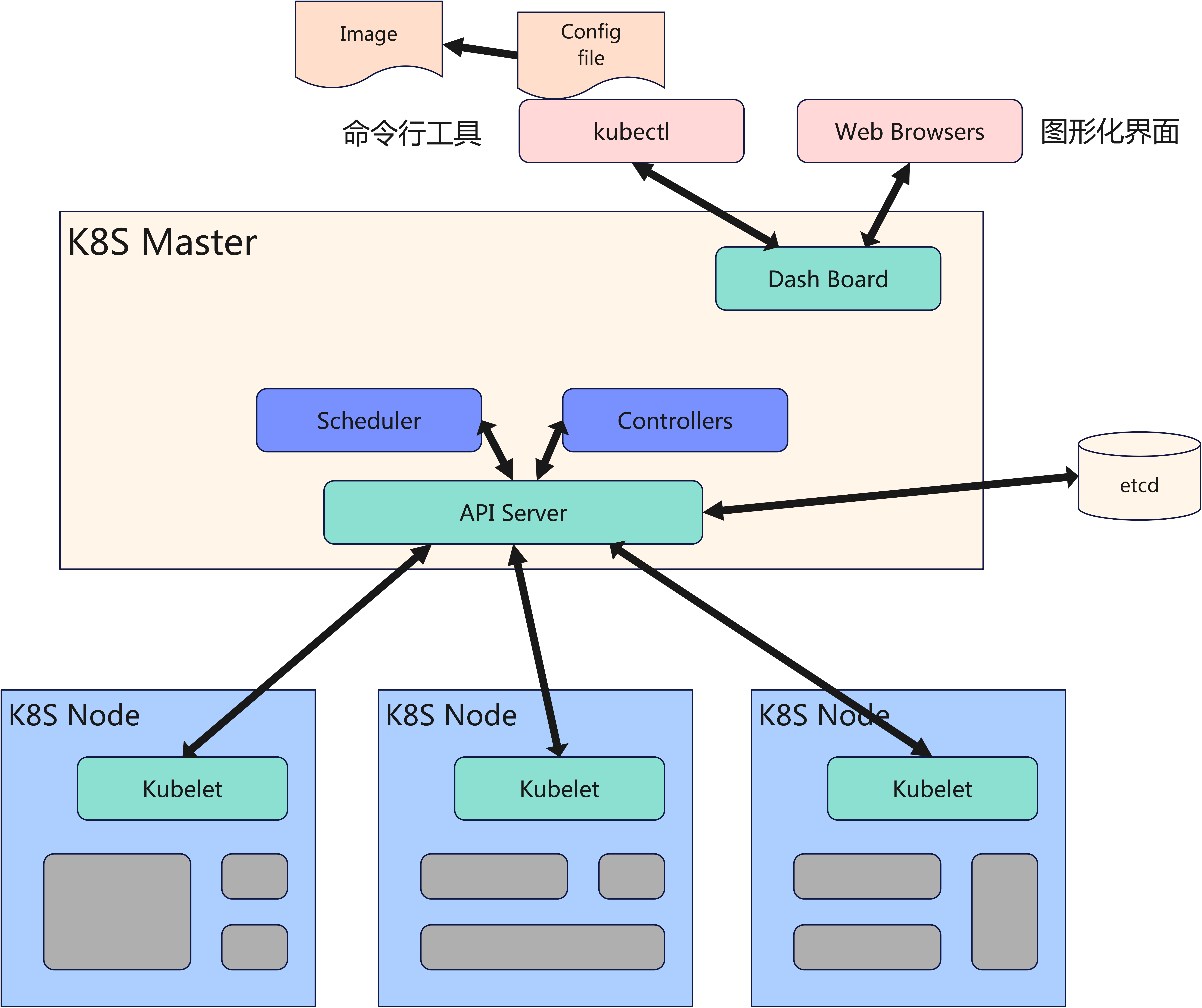
两个大组件:
- master: 集群管理 + 容器元数据管理
- master上的主要组件是 api-server + 一大堆的控制器
- worker(node): 容器的生命周期管理
- node上主要的组件就是 kubelet (容器管理)+ kube-proxy(流量负载均衡)
1.2 K8S 业务架构
K8S 业务架构:
- 容器元数据管理 (管理镜像地址、资源信息、部署的副本数量、部署的节点信息,对外暴露的端口信息等等)
- 容器生命周期管理 ( 管死管生管过程)
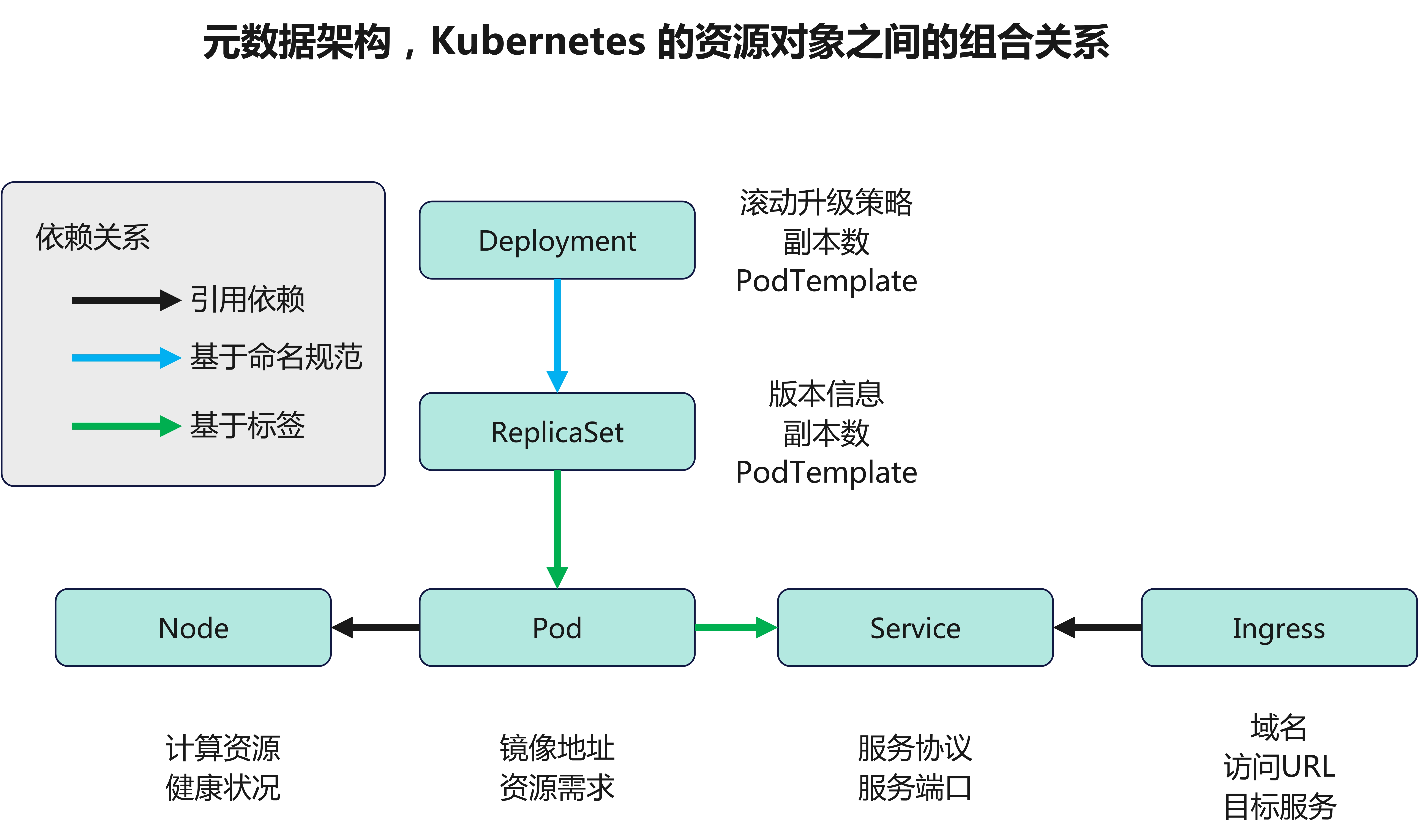
- Master: 集群控制节点,每个集群需要至少一个master节点负责集群的管控
- Node: 工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的docker负责容器的运行
- Pod: kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
- Service: pod对外服务的统一入口,下面可以维护着同一类的多个pod
- Label: 标签,用于对pod进行分类,同一类pod会拥有相同的标签
- Replication Controller:
- Replication Controller 保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个。
- 和直接创建的pod不同的是,Replication Controller会替换掉那些删除的或者被终止的pod,不管删除的原因是什么(维护阿,更新啊,Replication Controller都不关心)。
- 基于这个理由,我们建议即使是只创建一个pod,我们也要使用Replication Controller。
- Replication Controller 就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个node上的pod,Replication Controller 会委派本地容器来启动一些节点上服务(Kubelet ,Docker)。
- ReplicaSet:
- ReplicaSet是下一代复本控制器。ReplicaSet和 Replication Controller之间的唯一区别是现在的选择器支持。Replication Controller只支持基于等式的selector(env=dev或environment!=qa),但ReplicaSet还支持基于集合的selector(version in (v1.0, v2.0)或env notin (dev, qa))。
- 在使用时官方推荐ReplicaSet。
- Deployment:
- 为Pod和ReplicaSet提供了一个声明式定义(declarative)方法,用来替代以前的 ReplicationController 来方便的管理应用。
- 典型的应用场景包括:
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
more:
- NameSpace: 命名空间,用来隔离 pod 的运行环境
- Controller: 控制器,通过它来实现对 pod 的管理,比如启动 pod、停止 pod、伸缩 pod 的数量等等
- kube-proxy: kube-proxy通过采用iptables + ipset + ipvs的方式实现了其提出的Service的概念,即为符合条件的Pod提供负载均衡。
- IPVS: IPVS就是LVS项目下为Linux系统提供四层负载均衡的一个工具。
- https://blog.csdn.net/qiqi_6666/article/details/130546935
- IPVS: IPVS就是LVS项目下为Linux系统提供四层负载均衡的一个工具。
1.3 K8S 容器管理流程架构
从容器管理的入口, 到最终容器的创建, 具体流程如下图所示:
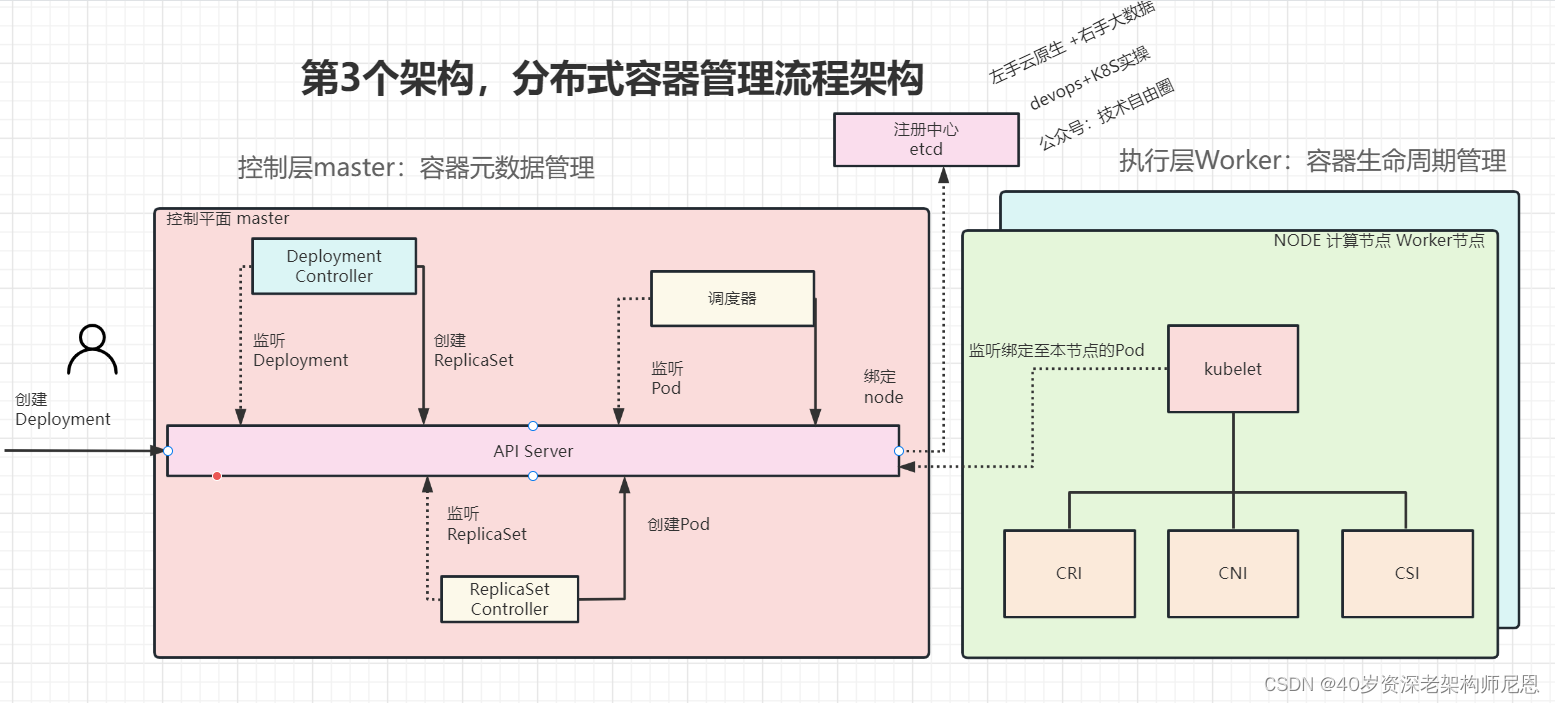
- 第一步: 用户向APIServer (数据总线)提交一份 部署文件,里边有用户视角的 容器元数据信息
- 第一步: APIServer 通知 一系列的控制器进行 部署文件处理, 得到最终的 元数据 对象,也就是 资源对象,持久化到 etcd,并且发布到 Node节点的 kubelet组件
- 第三步: Node节点的 kubelet组件判断是否属于自己管理的容器,如果是,则进行容器的创建
创建容器时,主要用到下面三个接口
- (1)CRI(Container Runtime Interface):
- 容器运行时接口,提供计算资源。
- kubernetes1.5版本之后,kubernetes项目推出了自己的运行时接口api–CRI(container runtime interface)。
- (2)CNI(Container Network Interface):
- 容器网络接口,提供网络资源。
- 是和 CoreOS 主导制定的容器网络标准,它本身并不是实现或者代码,可以理解成一个协议。CNI旨在为容器平台提供网络的标准化。容器平台可以从CNI获取到满足网络互通条件的网络参数(如IP地址、网关、路由、DNS等)。
- (3)CSI(Container Storage Interface):
- 容器存储接口,提供存储资源。
- 由 kubernetes、Mesos、Docker 等社区成员联合制定的一个行业标准接口规范,旨在将任意存储系统暴露给容器化应用程序。
- kubernetes 1.9 版为alpha阶段–>kubernetes 1.10版为beta阶段–>kubernetes 1.13 GA。
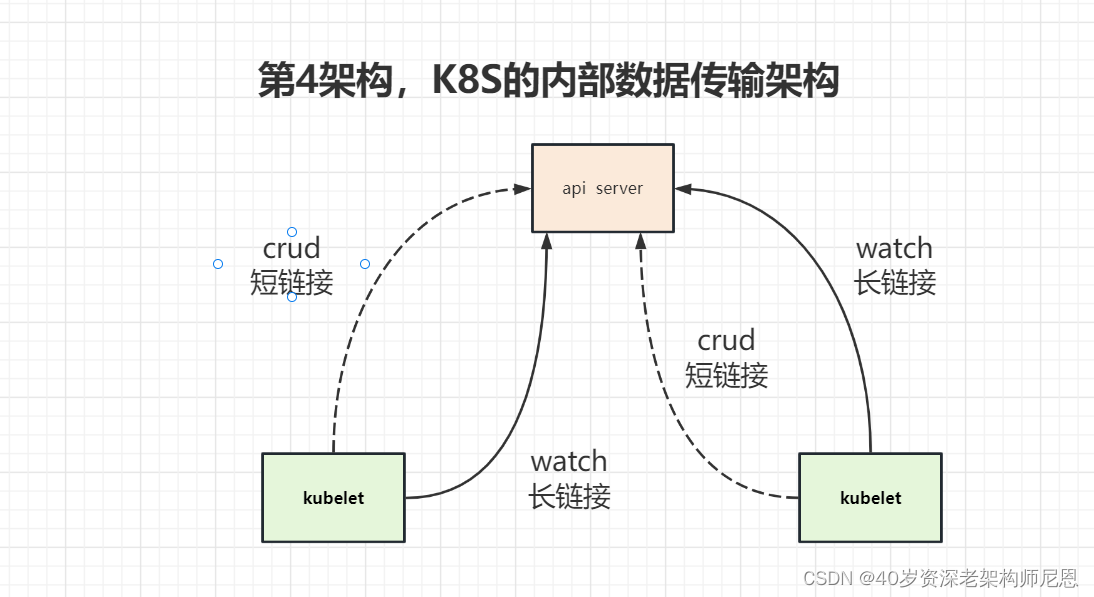
1.4 容器元数据的数据传输架构
内部的 api server 和 kublet 客户端 组件之间, 通过 长短链接 相结合的方式,完成高性能数据传输:
- 长连接: 进行增量元数据 推送 , 推模式
- 短连接: 进行全量元数据 拉取 , 推模式
1.5 容器对外暴露架构图
两个阶段:
- 元数据对象创建的阶段: 完成容器的选择, 容器建立,以及端口的映射
- 流量路由阶段: 由 kube-proxy组件 进行 流量的分发,和 pod 之间的负载均衡
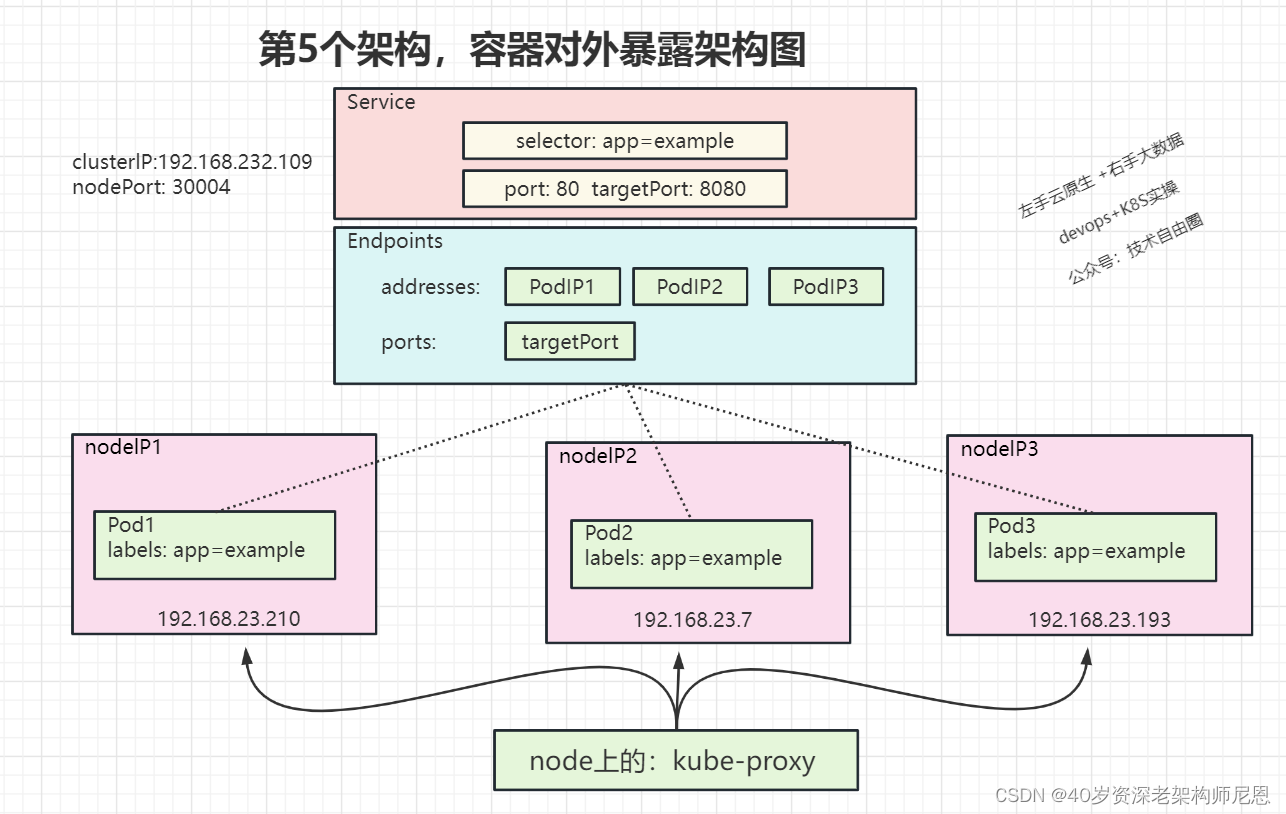
1.6 总的架构图
有了前面的基础之后,来一个总的架构图
K8S,是一个围绕容器打造的分布式系统,和其他的分布式系统比如rocketmq、kafka、elasticsearch,其实宏观上非常类似
两个大组件:
- master : 集群管理+元数据管理
- master上的主要组件是 api-server + 一大堆的控制器
- worker(node): 容器的生命周期管理
- node上主要的组件就是 kubelet (容器管理)+ kube-proxy(流量负载均衡)
另外通过etcd 进行元数据的持久化。
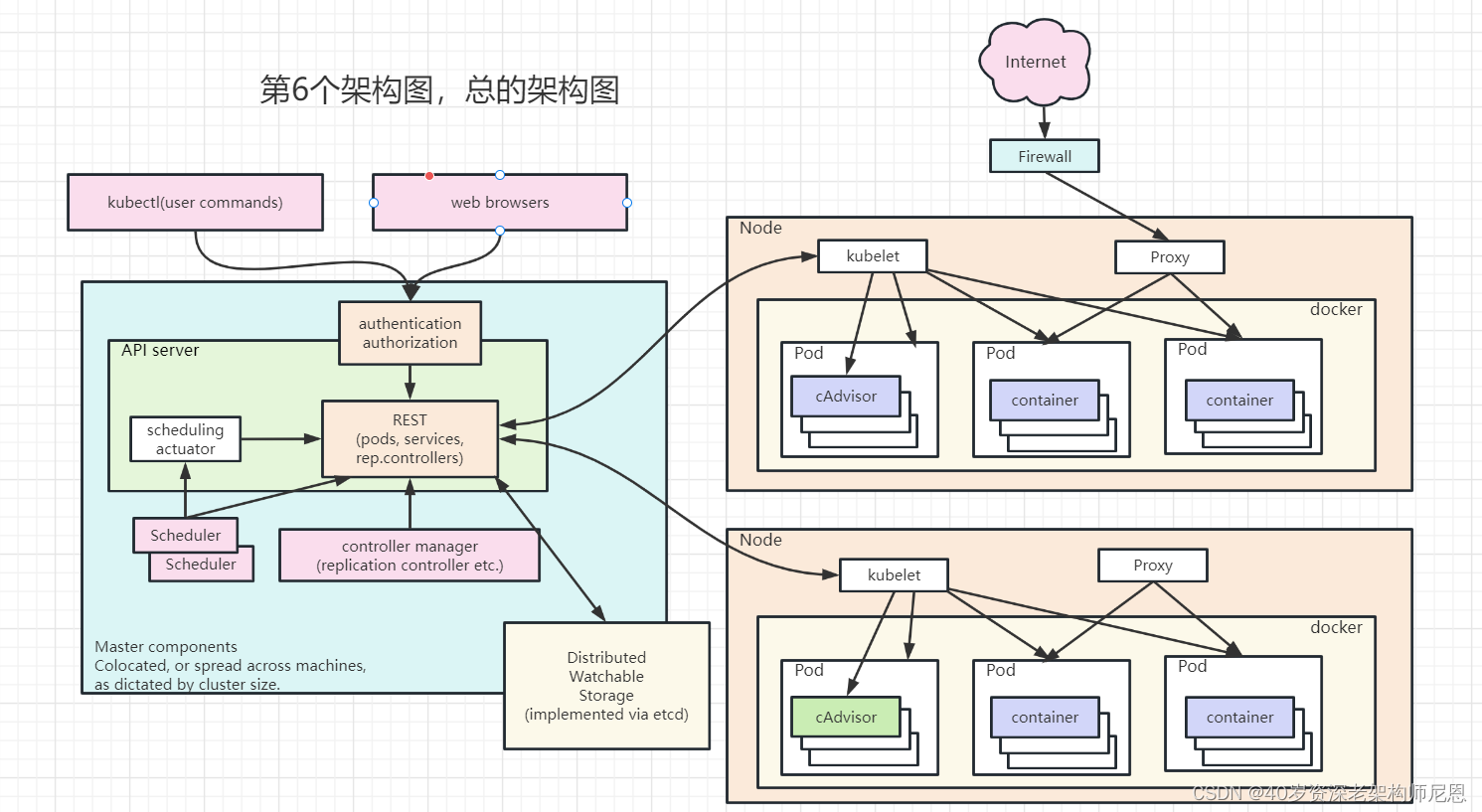
1.7 master 上APIServer 内部架构图
Kube-APIServer是Kubernetes最重要的核心组件之一,主要提供以下功能:
- 提供集群管理的REST API接口,包括∶认证Authentication、 授权Authorization、准入Admission( Mutating&Validating )。
- 提供其他模块之间的数据交互和通信的枢纽(其他模块通过APIServer查询或修改数据,只有APIServer才直接操作etcd)。
- APIServer提供etcd数据缓存以减少集群对etcd的访问。
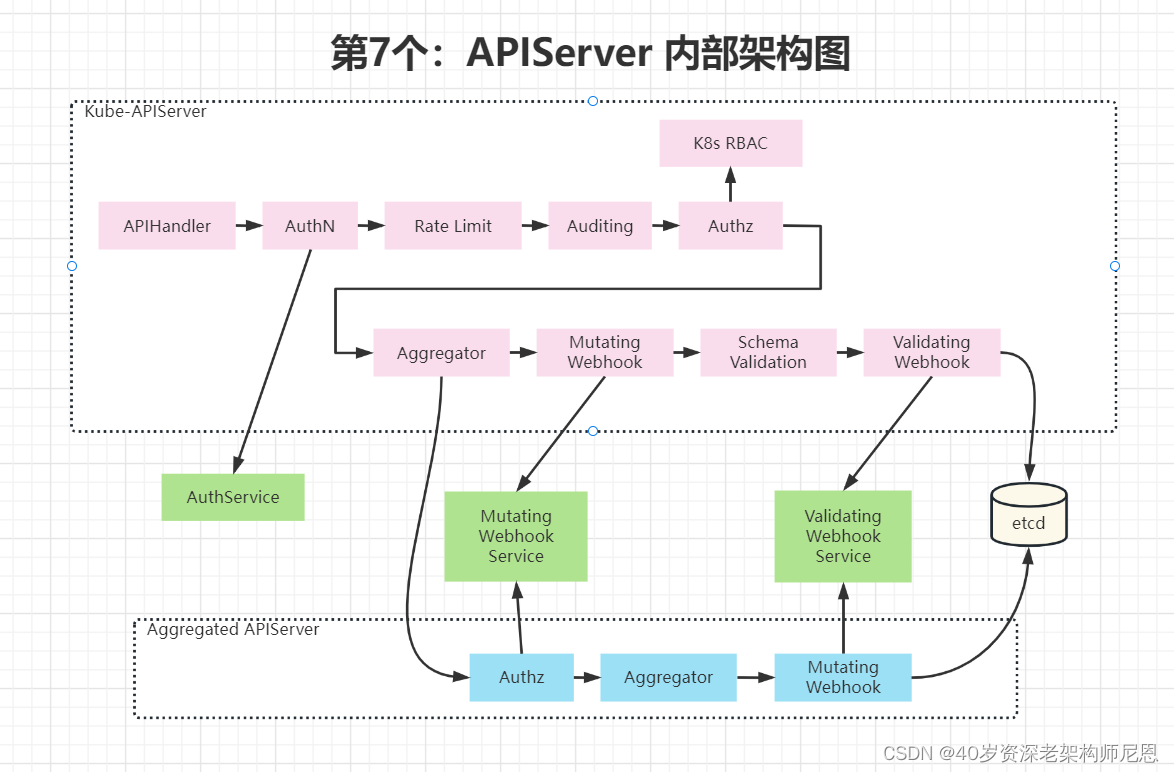
APIServer对请求的处理流程,采用了类似 责任链 模式的架构, 由很多的处理器组成:
- (1)APIHandler:APIServer 本质上是一个 RestServer,那么就需要注册不同对象的Handler
- (2)AuthN:认证,除了可以使用Kubernetes 自带的认证机制外,还可以使用 webhook自己定义一些认证机制。当配置了外部的认证机制后,认证请求就可以被转发到外部去,这样就可以去集成企业统一的认证平台
- (3)Rate Limit:限流
- (4)Auditing:审计,所有的操作都会生成一条日志记录
- (5)AuthZ:认证,可以使用 k8s 自带的 RBAC(role-base access control),也可以使用 webhook 自定义
- (6)Aggregator:
- 可以像 nginx 一样做路由配置,如果 APIServer 是标准的 K8S APIServer,就会走默认的 K8S APIServer,包括Mutating、Validation等;
- 如果是自定义的 APIServer,就会走Aggregated APIServer(自定义、独立部署的 APIServer),包括自定义的Mutating、Validation等。
- (7)Mutating:变形,可以加一些属性
- (8)Validating:验证,加完属性后再做一些验证
1.8 worker上 kubelet内部架构图
Kubelet 将 容器运行时, 容器网络和 容器存储抽象成了CRI,CNI,CSI。
此组件是运行在每一个集群节点上的代理程序,它确保pod 中的容器处于运行状态。 kubelet通过多种途径获取PodSpec定义,并确保PodSpec定义中所描述的容器处于运行和监控的状态。
node节点上创建、删除容器并利用探针进行健康性检查,向apiserver汇报pod状态和资源利用率,只要在节点上有操作动作,都归kubelet管
主要的工作为:
- (1)Kubelet 是node上 Kubernetes的初始化系统(init system)
- (2)Kubelet 从不同源获取Pod清单,并按需求启停Pod的核心组件:
- 可从本地文件目录获取Pod 清单
- 从给定的HTTPServer或Kube-APIServer等源头获取Pod 清单;
- (3)Kubelet负责汇报当前节点的资源信息和健康状态;
- (4)Kubelet负责Pod的健康检查和状态汇报。
1.9 worker 上 kube-proxy
kube-proxy 是一个网络代理程序,运行在集群的每一个节点上,是实现kubernets Service概念的重要部分。
kube-proxy 在节点上维护网络规则,这些规则可以在集群内外正确的于Pod进行网络通信.
kube-proxy 在node节点维护iptables转发和ipvs规则,保持容器间的正常网络通讯,
1.9.1 kube-proxy工作模式
kube-proxy目前支持三种工作模式:
- userspace模式
- userspace模式下,kube-proxy会为每一个Service创建一个监听端口,
- 发向ClusterIP的请求被iptables规则重定向到kube-proxy监听的端口上,
- kube-proxy根据LB算法 (负载均衡算法)选择一个提供服务的Pod并和其建立连接,以便将请求转发到Pod上。
- iptables模式:
- iptables模式下,kube-proxy为Service后端的每个Pod创建对应的iptables规则,直接将发向ClusterIP的请求重定向到一个Pod的IP上。
- ipvs模式:
- ipvs模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs规则。
- ipvs相对iptables转发效率更高,除此之外,ipvs支持更多的LB算法。
- 开启ipvs (必须安装ipvs内核模块,否则会降级为iptables)
区别:
- 由于userspace模式因为可靠性和性能(频繁切换内核/用户空间)早已经淘汰,所有的客户端请求svc,先经过iptables,然后再经过kube-proxy到pod,所以性能很差。
- IPVS模式与iptables同样基于Netfilter,但是ipvs采用的hash表,iptables采用一条条的规则列表。
- iptables又是为了防火墙设计的,集群数量越多iptables规则就越多,而iptables规则是从上到下匹配,所以效率就越是低下。
- 因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能
文档:
- https://blog.csdn.net/qq_36807862/article/details/106068871
K8S基础概念
- K8S集群:是一组节点,这些节点可以是物理服务器或者虚拟机之上安装了
- K8S平台:是一个围绕容器打造的分布式系统,和其他的分布式系统比如rocketmg、kafka、elasticsearch在宏观上是非常类似的。
etcd: 是Kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为etcd数据提供备份计划。
- pod:
- K8s应用最终以Pod为一个基本单位部署
- Pod安排在节点上,包含一组容器和卷.
- 同一个Pod里的可以有一个容器,也可以多个容器
- 同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。Pod是短暂的,不是持续性实体。
- 深入理解pod
- Label
- 很多资源都可以打标签
- 一些pod有Label,一个 Label 是 attach 到 pod 的一对键值对,用来传递用户定义的属性.
- 比如通过label来标记前端pod容器,使用label标记后端pod容器。
- 然后使用selectors选择带有特定label的pod。
- Deployment
- 应用部署用它,deployment最终会产生Pod
- 深入理解Deployment
- Service
- 负载均衡机制
- Addons
- Addons使用k8s资源 ( DaemonSet,Deployment等)实现集群级别的功能特性
- Addons 可以理解为 附件,扩展,插件
- Addons 由于提供集群级别的功能特性
- Addons 使用到的kubernetes 资源都放在kube-system名称空间下
- 以下为常用的Addons
- (1) DNS :集群内布DNS解析
- (2) dashborad:用户图形界面
- (3) resource-usage-monitoring: 容器资源监测
- (4) Cluster-level Logging: 集群层面日志
- 除了DNS Addon以外,其他的addon都不是必须的,所有的kubernetes 集群都应该有Cluster DNS
- DNS
- Cluster DNS是一个DNS 服务器,是对您已有环境中其他 DNS 服务器的一个补充,存放了Kubernetes Service 的 DNS 记录.
- Kubernetes 启动容器时,自动将该 DNS 服务器加入到容器的 DNS 搜索列表中
- Web UI (Dashboard)
- Dashboard(opens newwindow)是一个Kubernetes集群的Web 管理界面。用户可以通过该界面管理集群。
- k8s对象:k8s里面操作的资源实体,就是k8s的对象,可以使用yaml来声明对象
- 什么是k8s对象:
- 多个资源对象的yaml文件,比如Deployment和Service ,可以放在一个文件,可以放在不同的yaml文件中单独执行,
- 如果放在同一个yam1文件中,需要用连续的三个短横线隔开
- Kubernetes 资源对象,都是使用 API对象来配置kubernetes 推荐使用配置文件 运行一个或者多个容器,当然也支持命令行方式。API对象 的配置文件可以是:
- yaml格式的文件
- json 格式的文件
- 注:
- yaml文件比较易读,因此后面都会使用 yaml风格的文件去描述一个kubernetes 对象的各种属性。
- 即: 把容器的定义、参数、配置,统统记录在一个 YAML 文件中。
- 然后用这样一句指令把它运行起来:
kubectl apply -f 资源对象的配置文件- 例子:
kubectl apply -f demo-Provider.yml
- 像这样的一个YAML文件,对应到 Kubernetes 中,就是一个API Object (API对象)
- 理解01:
- 一个Kubernetes对象代表着用户的一个意图 (arecord ofintent),
- 一旦您创建了一个Kubernetes对象,Kubernetes将持续工作,以尽量实现此用户的意图。
- 创建一个Kubernetes对象,就是告诉Kubernetes,您需要的集群中的工作负载是什么(集群的 目标状态)。
- k8s对象,通过etcd持久化:
- Kubernetes对象指的是Kubernetes系统的持久化实体,所有这些对象合起来,代表了你集群的实际情况。
- 常规的应用里,我们把应用程序的数据存储在数据库中,Kubernetes将其数据以Kubernetes对象的开式通过 api server存储在 etcd 中。
- 具体来说,这些数据(Kubernetes对象)描述了:
- 集群中运行了哪些容器化应用程序 (以及在哪个节点上运行)
- 集群中对应用程序可用的资源 (网络,存储等)
- 应用程序相关的策略定义,例如,重启策略、升级策略、容错策略其他Kubernetes管理应用程序时所需要的信息
- k8s对象文件字段含义:
- 什么是k8s对象:
- k8s管理资源:
- 三种方式:
- 命令式对象:
kubectl 命令 资源类型 资源名称 (其他参数) - 命令式对象配置:
kubectl命令+yaml文件 - 声明式对象配置:
基本上同命令式对象配置,但只有apply命令
- 命令式对象:
- 注意:
- 同一个Kubernetes对象应该只使用一种方式管理,否则可能会出现不可预期的结果
- 文档:
- https://blog.csdn.net/weixin_64334766/article/details/134107334
- 三种方式:
- k8s API:
- 概念:
- k8s是分布式系统,它本身有各个组件,本身各个组件之间的通信,对外提供的都是rest接口的http服务。
- 这些接口就统称为 k8s API。
- API分组:
- k8s的api也很有特点,首先它是分组的,它有很多api组。
- 这些api组都有不同的功能,有的api组负责权限,有的api组负责存储。
- API分组版本:
- 每个api组还有版本的区分,它其实也有大小版本区分,但是不是我们常用的1.1.1这种版本号,
- k8s api大的版本都是以v1,v2 这种为迭代的,
- 每个大的版本里面区别三个等级
- Alpha等级,这个等级就是还在调试的,基本我们不作为开发者的话,这种等级的接口版本不会接触到。
- 比如v1alpha2,就代表是v1大版本的alpha等级第2小版本.
- Beta等级,这个等级说明接口基本可以使用了,也经过完整测试了.
- 会比正常的稳定版本有更多的功能。它的版本格式如v1beta2.
- Stable版本,这个等级说明这个是个稳定版,可以放心使用。
- Alpha等级,这个等级就是还在调试的,基本我们不作为开发者的话,这种等级的接口版本不会接触到。
- 查看 k8s api 版本:
kubectl api-versions
- 概念:
100 简单总结
100.1 k8s简单宏观理解
- 从业务上讲,k8s主要进行2个管理:
- 容器元数据管理: (管理镜像地址、资源信息、部署的副本数量、部署的节点信息,对外暴露的端口信息等等)
- 容器生命周期管理: ( 管死管生管过程)
- 从宏观上看,K8S是一个围绕容器打造的分布式系统,和其他的分布式系统比如rocketmq、kafka、elasticsearch,其实宏观上非常类似.
- 有2个大组件: master, worker(node)。
- master: 集群管理 + 容器元数据管理
- master上的主要组件是 api-server + 一大堆的控制器
- worker(node): 容器的生命周期管理
- node上主要的组件就是 kubelet (容器管理)+ kube-proxy(流量负载均衡)
- 一旦 kubernetes 环境启动之后,master 和 node 都会将自身的信息存储到 etcd 数据库中。
- 先不聚焦到具体的元数据和生命周期如何管理,先来看从创建Deployment,到启动pod,都经历了什么:
- master:
- Deployment Controller: 监听 Deployment 的变化,当有新的 Deployment 创建时,会创建一个 ReplicaSet
- ReplicaSet Controller: 监听 ReplicaSet 的变化,当有新的 ReplicaSet 创建时,会创建 pod
- Scheduler:
- 监听Pod的变化,当有新的 Pod 创建时,会根据Pod的调度策略,将 Pod 调度到合适的节点上,得到合适的节点后,得到元数据对象
- 将元数据对象:
- 持久化到 etcd
- 发布到 Node 节点的 Kubelet 上
- worker(node):
- Kubelet: 判断是否属于自己的管理容器,如果是,则会通知 docker,进行容器的创建、启动、健康检查、状态汇报。
- 创建容器时,主要用到3个接口: CRI(容器运行时接口), CNI(容器网络接口), CSI(容器存储接口)
- Kubelet: 判断是否属于自己的管理容器,如果是,则会通知 docker,进行容器的创建、启动、健康检查、状态汇报。
- master:
MARK: wait to complete.
- service, endpoint区别
- CAdvisor是什么
- 创建deployment时,pod, endpoint, service, ingress, kube-proxy的关系是什么样的
- 挂载的过程是怎么样的,挂载远端目录呢?比如nfs?
- cluster ip, node ip, service ip区别
- node port forwarding
100.2 容易混淆的词
- Minikube: 是一种可以在本地轻松运行一个单节点Kubernetes集群的工具
- minikube 只能够搭建 Kubernetes 环境,要操作 Kubernetes,还需要另一个专门的客户端工具kubectl.
- Kubectl: 是一个命令行工具,可以使用该工具控制Kubernetes集群管理器,
- 如检查群集资源,创建、删除和更新组件,查看应用程序。
- kubectl是API,供我们调用,键入命令对k8s资源进行管理.
- kubectl 的作用有点类似之前我们学习容器技术时候的工具 docker
- 它也是一个命令行工具,作用也比较类似,同样是与 Kubernetes 后台服务通信,把我们的命令转发给 Kubernetes,实现容器和集群的管理功能。
- kubectl 是一个与Kubernetes、minikube 彼此独立的项目,所以不包含在 minikube 和 kubernetes 里。
- Kubelet: 是一个代理服务,它在每个节点上运行,并使从服务器与主服务器通信。
- kubelet 用来调用下层的container管理器,从而对底层容器进行管理。
- kubeadm: 是管理器,我们可以使用它进行k8s集群的安装、节点的管理。
- 最常用的功能有三个:
- (1) init: 初始化k8s节点,运行此命令来搭建 Kubernetes 控制平面节点
- (2) join: 将worker节点加入到k8s集群
- (3) reset: 尽最大努力还原init或者ioin对集群的影响
- 最常用的功能有三个: